定义
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt同时发现,因此人们称它为克努特——莫里斯——普拉特操作(简称KMP算法)。
部分算法比较 [克努斯-莫里斯-普拉特算法即KMP算法]
令 m 为模式的长度, n 为要搜索的字符串长度, k为字母表长度
图例
有一个字符串 Str1 = “BBC ABCDAB ABCDABCDABDE”,判断里面是否包含另一个字符串 Str2 = “ABCDABD”?
首先,字符串”BBC ABCDAB ABCDABCDABDE”的第一个字符与搜索词”ABCDABD”的第一个字符,进行比较,因为B与A不匹配,所以搜索词后移一位.

B与A不匹配,搜索词再往后移.

一直重复,直到字符串有一个字符,与搜索词的第一个字符相同为止.

接着比较字符串和搜索词的下一个字符,还是符合.

直到字符串有一个字符,与搜索词对应的字符不相同为止.

这时候,想到的是继续遍历下一个字符,重复第1步。(其实是很不明智的,因为此时 BCD已经比较过了,没有必要再做重复的工作,一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是”ABCDAB”。 KMP算法的想法是,设法利用这个已知信息,不要把”搜索位置”移回已经比较过的位置,继续把它向后移,这样就提高了效率。).

怎么做到把刚刚重复的步骤省略掉?可以对搜索词计算出一张《部分匹配表》,这张表的产生在后面介绍.
已知空格与D不匹配时,前面六个字符”ABCDAB”是匹配的。查表可知,最后一个匹配字符 B 对应的”部分匹配值”为2,因此按照下面的公式算出向后移动的位数:[移动位数 = 已匹配的字符数 - 对应的部分匹配值] 因为6 - 2等于4,所以将搜索词向后移动4位.
因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2(”AB”),对应的”部分匹配值”为0。所以,移动位数 = 2 - 0,结果为2,于是将搜索词向后移2位;
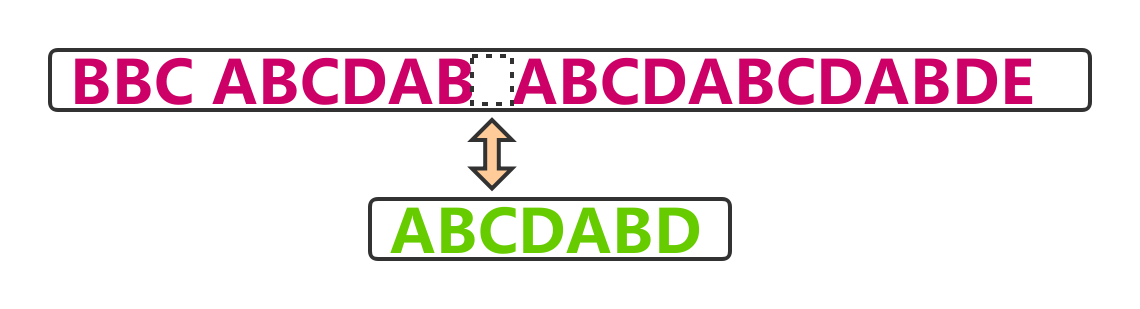
因为空格与A不匹配,继续后移一位.
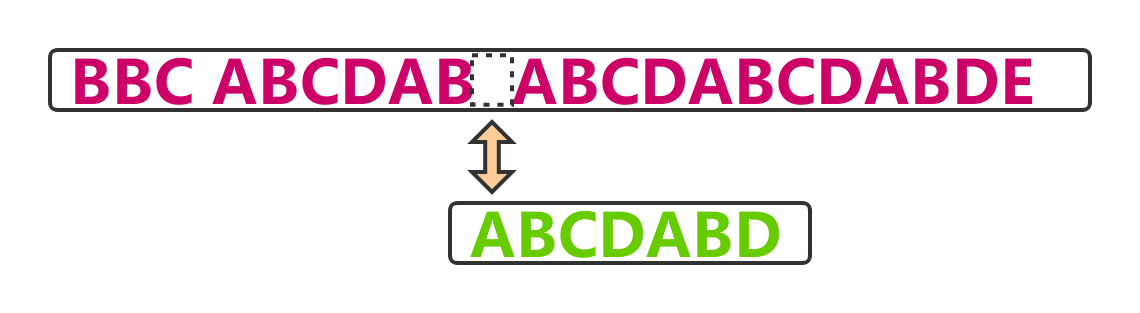
逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位.

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配), 移动位数 = 7 - 0,再将搜索词向后移动 7 位,这里就不再重复了.

部分匹配表
如何给字符串生成一个匹配表?
“部分匹配值”就是”前缀”和”后缀”的最长的共有元素的长度。

如何寻找前后缀?
- 找前缀时,要找除了最后一个字符的所有子串。
- 找后缀时,要找除了第一个字符的所有子串。
以”ABCDABD”为例,
2
3
4
5
6
7
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
按照定义,”ABCDAB”的部分匹配表即如下所示:
| 标号(j) | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 模式串(P) | A | B | C | D | A | B | D |
| 部分匹配值 | 0 | 0 | 0 | 0 | 1 | 2 | 0 |
“部分匹配值”的实质是,字符串头部和尾部会有重复。比如,”ABCDAB”之中有两个”AB”,那么它的”部分匹配值”就是2(”AB”的长度)。模式串移动的时候,第一个”AB”向后移动4位(字符串长度-部分匹配值),就可以来到第二个”AB”的位置。
next数组
根据KMP算法,在失配位会调用该位的next数组的值,下面我将详细道出next数组的来龙去脉。
next[i]表示在失配位i之前的最长公共前后缀的长度
粉红色部分表示已匹配成功

红色部分表示主串跟模式串已匹配部分

我们在上面说到“最长公共前后缀”,体现到下图所示的样子。
蓝色部分为最长公共前后缀的部分

next数组的作用是通过寻找最长公共前后缀的部分,快速移动模式串,从而提高字符串匹配的效率,如下图所示:
蓝色部分就是字符串最长公共前后缀
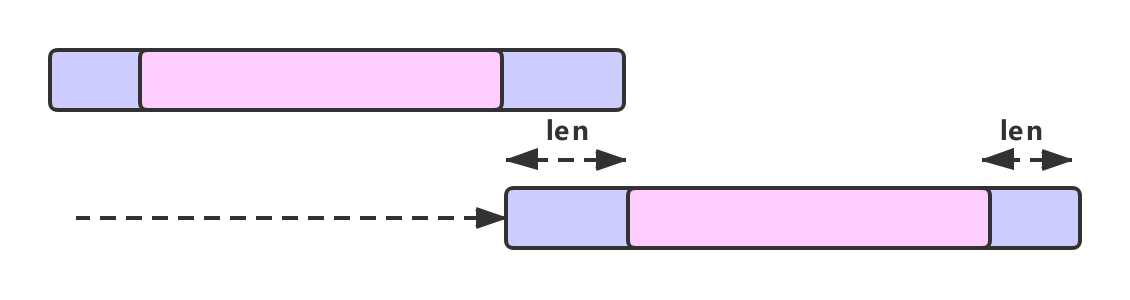
next[i]返回当前位置i的最长公共前后缀的长度,假设为 len 。因为数组是由 0 开始的,所以 next 数组让模式串的第 len 位与主串匹配就是拿最长前缀之后的第 1 位与失配位重新匹配,避免匹配串从头开始,如下图所示。
蓝色部分为最长公共前后缀的部分
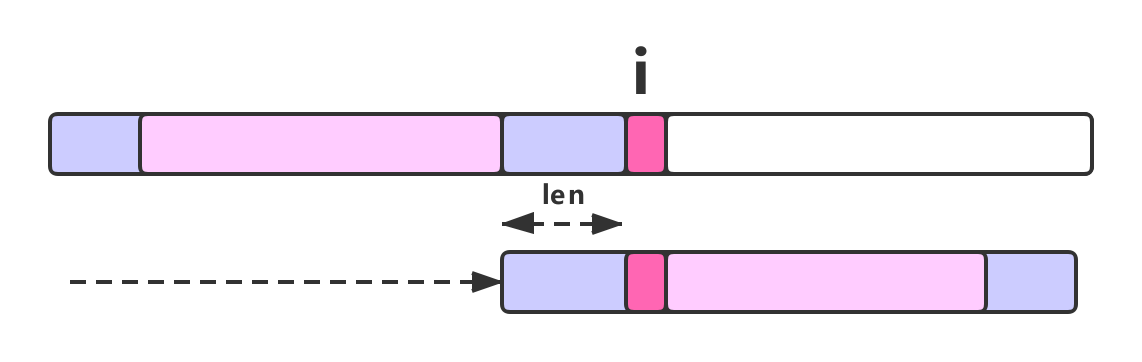
如果上图中的红色位置依然匹配失效,则需要对上图中的绿色部分再次去求解它的最长公共前后缀长度(假设为len),然后继续向右移动模式串,让模式串的第 len 位与主串的失配位重新进行匹配,如果仍旧不匹配,则继续以上过程操作。如下图所示:
蓝色部分为最长公共前后缀的部分
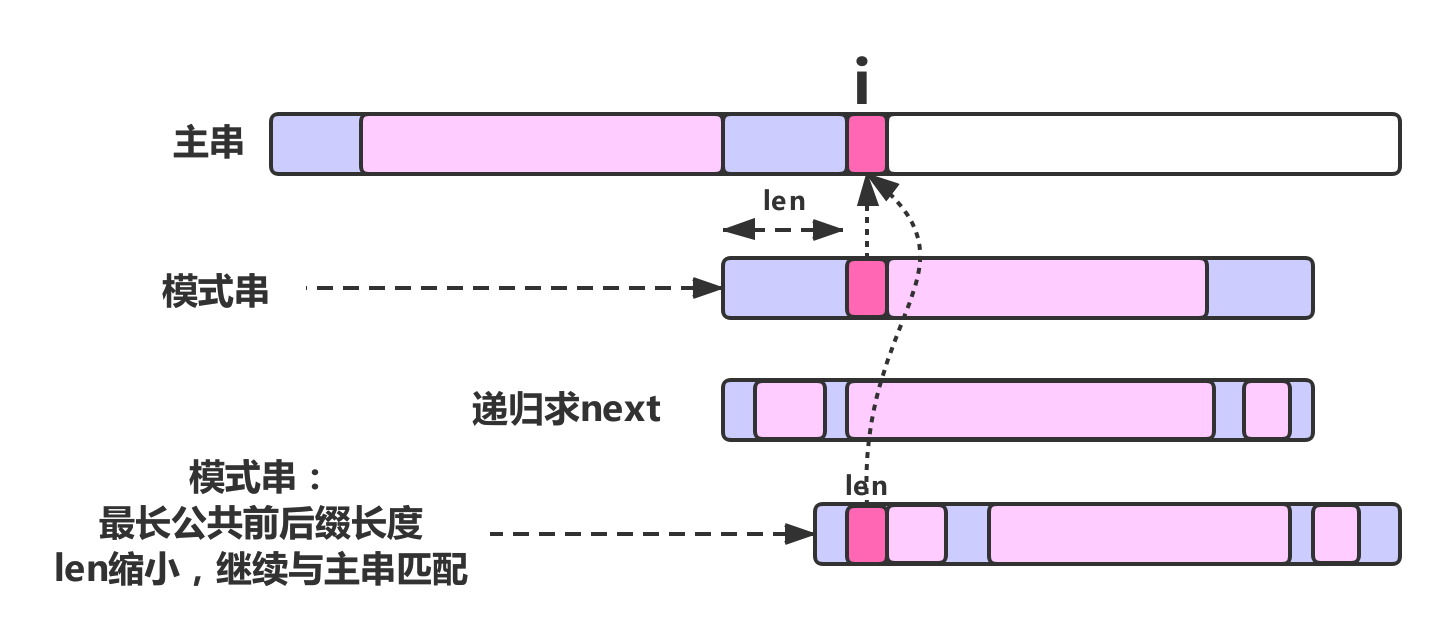
我们发现,当发生失配的时候,可以借助递推的思想,根据已知的结果继续求出当前失配位之前的最长公共前后缀的长度,然后,继续移动模式串,从而进行新一轮的字符串匹配。
next数组究竟如何求出呢?
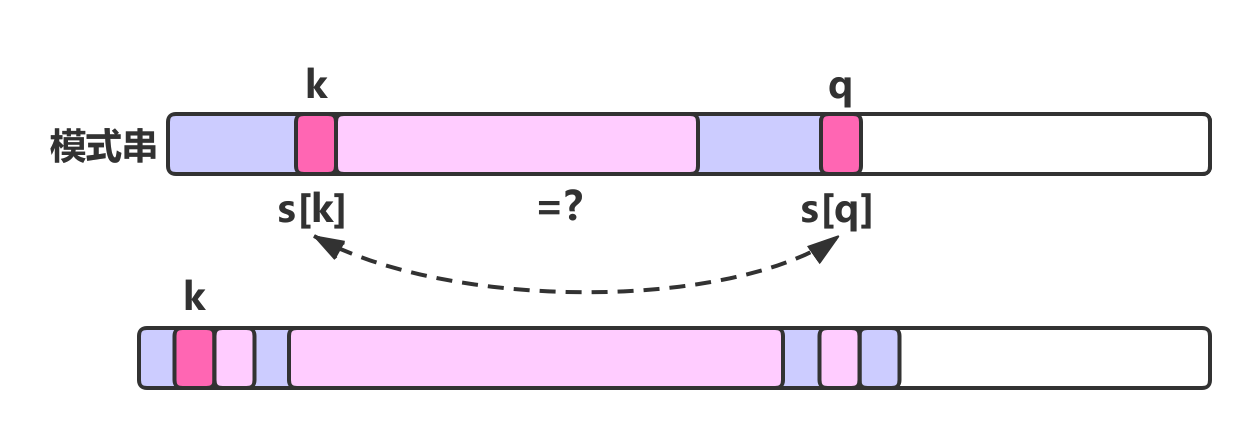
当红色部分相同(即S[k]==S[q])时,则当前 next 数组的值为上一次 next 的值加一(即next[q] = k++),如上图所示。
当红色部分不等的时候,则需要对绿色部分递推求解 k = next[k-1],然后再对新的 k 位置字符与 q 位置字符进行匹配,如果相等,则 next[q] = k +1,否则,执行递推匹配,直到k =0时递推结束。比如,模式串“ABCABXABCABC”,最后一个字符C的next数组值为3。(因为C之前的最长公共前后缀为“ABCAB”,而“ABCAB”的最长公共前后缀为“AB”,其长度为2,又源于第三个字符C与最后一个字符C匹配,所以最后一个字符C的next数组值为3)
PHP代码实现
1 | class KMP |
运行结果
1 | Array |
